Categoría: Web 2.0
Comparativa de Foros Open Source: Qué foro elegir

En la antigua Roma un foro era el lugar donde solía desarrollarse el mercado y constituía la puerta de entrada de la ciudad donde personas de todo el mundo entablaban contacto y se relacionaban para intercambiar opiniones y cerrar acuerdos. Visto así podríamos extrapolar esta misma idea hasta hoy en día, y es que un foro constituye una puerta de entrada y un punto de reunión para los usuarios de una web. Además no debemos pasar por alto la utilidad de un foro como herramienta de promoción en buscadores y fidelización de visitantes.
Existen infinidad de sistemas de Foros, muchos de ellos gratuitos y otros además open source. Las cuatro soluciones más populares y con el respaldo de una comunidad mayor son Phpbb, Vanilla, MyBB y SMF. En el siguiente artículo de HelloGoogle podrá conocer en detalle estas cuatro soluciones antes de decidirse por una.
Phpbb 3

Demo: http://demo.forum-software.org/phpbb/
Versión actual estable: 3.0.4 (2007-01-28)
Autor: James Atkinson
Tecnología: PHP
Licencia: GPL
Brevemente: Es el sistema de foros más popular y extendido. Es una solución muy flexible que permite personalizarse a nivel de estilos y ampliarle en base a Mods. Cuenta con el respaldo de un gran comunidad de usuarios y desarrolladores.
Características:
- Gratuito y Open Source
- Foros y subforos ilimitados.
- Gestión inteligente del cacheo de archivos
- Búsqueda eficiente de temas y usuarios
- Paneles de administrador y de moderador independientes
- Encuestas
- BBCode
- Gestión eficiente de grupos de usuarios, moderadores o administradores
- Advertencia y reportes por usuarios a moderadores ante posts indebidos
- Perfil de usuario configurable y escalable.
- Es posible adjuntar Múltiples archivos
- Repositorio con muchos Mods y templates gratuitos desarrollados por la comunidad
- Gestión y asignación sencilla de rangos por posts o por grupos
- Log de acciones de usuarios.
- Gestión de Backups y RollBascks de la base de datos.
Vanilla

Demo: http://demo.forum-software.org/vanilla/
Versión actual estable: 1.0.3 (04-12-2006)
Autor: Mark O’Sullivan
Tecnología: PHP
Licencia: GPL
Brevemente:
Es un sistema de foros open source muy ligero (386k) desarrollado en PHP y MySQL. Es una solución flexible que puede ampliarse a base de add-ons.
Características:
- Cumple los estándares W3C y las plantillas son documentos validos XHTML y CSS.
- Sistema de gestión de plantillas muy flexible y eficiente que permite integrar el foro en un Site ya diseñado.
- Gestión de usuarios ágil para integrar el foro con el myaccount de un Site (Single sign in)
- Desarrollado sobre el framework Lussumo Framework. Este framework pemite a los desarrolladores extender la plataforma añadiendo add-ons al core del foro.
- Existe a disposición de sus usuarios un extenso repositorio de extensiones en http://lussumo.com/addons.
- Sindicación RSS y Atom
- Sistema de Whispers para conversaciones privadas.
- Busqueda inteligente de posts, threads, recursos y usuarios.
- Sistema de bookmarking.
- Search-engine friendly URLs
- Gestión de Forum announcements.
- Animaciones y transiciones con JavaScript.
SMF
Url: http://www.simplemachines.org/
Demo: http://support.simplemachines.org/demo/index.php (user: test / pass: test)
Versión actual estable: 1.1.7 (07-11-2008)
Autor: Simple Machines
Tecnología: PHP
Licencia: Copyright
Brevemente: Es una solución gratuita pero no Open Source. Cuenta con el respaldo y soporte de una gran comunidad. Existe una gran cantidad de recursos gratuitos disponibles para ampliar y customizar la plataforma.
Características:
- Abstracción respecto a la BD: PostgreSQL, SQLite y MySQL.
- Instalación y configuración sencilla..
- Moderación centralizada de post, topics, adjuntos, etc.
- Sistema de advertencia a usuarios.
- Gestión eficiente de grupos y permisos.
- Editor de posts y threads WYSIWYG
- Gestión de permisos eficiente.
- Gestión del cacheo de archivos eficiente para maximizar el rendimiento del sistema.
- Gestión de colas de correo para mensajería interna..
- Perfil de usuario configurable y escalable.
- OpenID.
MyBB

Demo: http://www.opensourcecms.com/index.php?option=content&task=view&id=2124&Itemid=159
Versión actual estable:1.4.4 (27-11-2008)
Autor: MyBB Group
Tecnología: PHP
Licencia: GPL
Brevemente: Es un paquete para desarrollar un sistema de foros desarrollado por una comunidad muy activa de desarrolladores, ofrece un Interfaz muy intuitivo, un sistema flexible y muchas actualizaciones periódicas de seguridad.
Características:
- Cantidad ilimitada de foros y subforos, usuarios registrados, temas visuales y mensajes almacenados.
- Buscador integrado.
- Fácil instalación de plugins y modificaciones sin necesidad de manipular el código.
- Posibilidad de tener varios idiomas, temas visuales y plantillas activos al mismo tiempo en el foro, para que los usuarios puedan elegir entre ellos.
- Suscripciones a foros y temas, notificaciones por email, lista de temas favoritos y lista de amigos.
- Perfiles personalizables y mensajería privada.
- Permite la moderación masiva de temas
- Se pueden crear campos nuevos para los perfiles de usuarios.
- Posibilidad de ocultar foros, haciéndolos invisibles a invitados, o bien haciendo que sea necesario el registro para visualizarlos.
- La plantilla puede ser editada directamente con HTML.
- Herramienta de backup de la base de datos integrada, así como herramientas para optimizarla y corregir errores en el conteo de estadísticas, de modo automático.
- La instalación y la actualización a posteriores versiones se realiza de manera rápida y sencilla.
Comparativa
| MyBB | PhpBB 3 | Simple Machines Forum | Vanilla | |
|---|---|---|---|---|
| Licencia | GPL License | GPL License | Licencia | GPL License |
| Version | 1.4.2 | 3.0.2 | 1.1.rc3 | 1.0 |
| Última revisión | 17 Septiembre 2008 | 10 Julio 2008 | 19 Agosto 2006 | 5 Julio 2006 |
| Demo | Demo on-line | Demo on-line | Demo on-line | Demo on-line |
| Web Site | Web Site | Web Site | Web Site | Web Site |
| Descarga | Descargar | Descargar | Descargar | Descargar |
| Instalación | (Sencillo) | (Muy Sencillo) | (Sencillo) | (Normal) |
| Administración | (Sencillo) | (Sencillo) | (Sencillo) | (Normal) |
| Uso del foro | (Sencillo) | (Muy Sencillo) | (Sencillo) | (Sencillo) |
| Opinión expertos |   |
 |
|
|
| Opinión comunidad | |
|
|
|
| Arquitectura del servidor | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| Sistema Operativo |
|
|
|
|
| Servidor Web |
|
|
|
|
| Lenguajes |
|
|
|
|
| Bases de Datos |
|
|
|
|
y accesibilidad |
MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| CrossBrowsing |
|
|
|
|
| Tecnología o Plugins |
|
|
|
|
| HTML / XHTML |
|
|
|
|
| CSS |
|
|
|
|
| Accesibilidad (WAI) |
|
|
|
|
| Normas W3C |  Sí Sí |
Sí |
Sí |
Sí |
| Localización | Sí |
Sí |
Sí |
Sí |
| Friendly URLs | Sí |
 Patch Patch |
Sí |
Plugin |
| Características Técnicas | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| Soporte UTF-8 | Sí |
Sí |
Sí |
Sí |
| Integración con CMS / Blog |
|
|
|
|
| Integración con BD de usuarios |
|
|
|
|
| Web Services / XML-RPC | No | No | No | No |
| Características principales | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| Sindicación | RSS 2.0 | Ninguno | RSS 2.0 | RSS 2.0 |
| Plugins | Sí |
Sí |
Sí |
Sí |
| Temas | Sí |
Sí |
Sí |
Sí |
| Sistema de votación (Poll) | Sí |
Sí |
Sí |
 No No |
| Mensajes privados | Sí |
Sí |
Sí |
Sí |
| Formulario edición Post |
|
|
|
|
| Formato edición Posts |
|
|
|
|
| BBCodes | Sí |
Sí |
Plugin |
 Sin datos Sin datos |
| Perfil de Usuario | Sí |
Sí |
Sí |
Sí |
| Gestión de Usuarios | Acceso restringido en foros específicos | Grupo de usuarios | Grupo de usuarios | Grupo de usuarios |
| Baneo de Usuarios | Sí |
Sí |
Sí |
Sí |
| Listado de Usuarios | Sí |
Sí |
No |
Sin datos |
| Calendario | Sí |
Sin datos |
Sí |
Sin datos |
| Características usuario | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| Posting anónimo | Sí |
Sí |
No |
No |
| Notificación por Email | Sí |
Sí |
Sí |
Sí |
| Emoticones | Sí |
Sí |
Sí |
No |
| Adjuntos | Sí |
Sí |
Sí |
No |
| Filtrado de palabras | Sí |
Sí |
Sí |
Sí |
| Ranking de usuarios | Sí |
Sí |
Sí |
Sin datos |
| Avatar de usuarios | Sí |
Sí |
Sí |
Sin datos |
| Firma de usuarios | Sí |
Sí |
Sí |
Sin datos |
| Rating/Karma | Sí
| No
| Sí
| Sí
|
| Perfil personalizable |
|
|
|
|
| Buscador | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| Búsqueda Full-text | Sí |
Sí |
Sí |
Sí |
| Búsqueda por autor | Sí |
Sí |
Sí |
Sí |
| Búsqueda Avanzada search | Sí |
Sí |
Sí |
Sí |
| Gestión no leidos | Trackeado en BD | Trackeado en BD | Trackeado en BD | Trackeado en BD |
| Notificación | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| RSS/ATOM | Sí |
No
|
Sí |
Plugin |
| Sí |
Sí |
Sí |
Plugin |
|
| Mensajería instantánea | Sí |
Jabber | Sin datos |
No
|
| Bookmarks | Sí |
Sí |
Plugin |
|
| Anti-Spam y Seguridad | MyBB | PhpBB 3 | Simple Machines Forum | Vanilla |
| Captcha | Sí |
Sí |
Sí |
Plugin |
| Grupos | Múltiples | Múltiples | Múltiples | Múltiples |
| Control de Flood | Sí |
Sí |
Sí |
Sí |
| ACLs | Sí |
Sí |
Sí |
Sí |
| Listas Negras | Sí |
Sí |
Sí |
Sí |
| Warnings | Sí |
Sí |
Plugin |
No |
| Suspensiones | Sí |
Sí |
Sí |
Sí |
| Baneos | Sí |
Sí |
Sí |
Sí |
| IP-Block | Sí |
Sí |
Sí |
No |
| Audit Logging | Sí |
Sí |
Sí |
No |
| Reporte Usuarios | Sí |
Sí |
Sí |
Plugin |
Ajax zoomy: Un Ajax lightbox para su galería de imágenes

Podemos encontrar infinidad de librerias para crear en nuestras webs el conocido efecto lightbox que viene a ser la versión 2.0 de los antiguos pop-ups. Me gustaría destacar Zoomy.js que es una librería basada en Prototype y Scriptaculous, desarrollada por Filippo Buratti que permite crear de manera sencilla y rápida una galería de imágenes tipo lightbox. Tiene la particularidad de que a pesar de ser un código realmente ligero (menos de 5kb) las imagenes se presentan de manera muy elegante y los pop-ups pueden ser arrastrados libremente por la pantalla.
Tomando este código como base, he añadido dos nuevas funcionalidades que creo pueden serle de mucha utilidad a la hora de desarrollar su propia galería:
- Contenido AJax: Ahora es posible mostrar en la ventana lightbox texto ó html.
<ul class="zoomyx">
<li><a href="(url del contenido AJAX)" style="background-image: url(url de la imagen)" title="Rubix Cube">Rubix Cube</a></li></ul> - Definir estilos css de la venta lightbox: Es posible definir en el atributo rel los estilos css (altura, anchura, etc) de la ventana lightbox.
<ul class="zoomyx">
<li><a href="(url del contenido AJAX)" rel="(estilos css)' style="background-image: url(url de la imágen)" title="Rubix Cube">Rubix Cube</a></li></ul>Nota: A la hora de definir los estilos es necesario seguir la nomenclatura que establece prototype a la hora de utilizar la función setStyle, por ejemplo:
rel="width:'400px',height:'400px',color:'#fff'"
El resto de funcionalidades de Zoomy se mantienen intactas, puede ver los cambios introducidos comparando la librería original con la librería ampliada en HelloGoogle.com. Además la nueva librería no sufre ningún incremento de peso (A penas medio kb).
He preparado una demo donde puede comprobar online el funcionamiento de la librería con todas sus funcionalidades.
Como siempre, puede descargarse el código completo de la librería y utilizarlo libremente en sus desarrollos. Recuerde que el código es open-source y está protegido por una Licencia MIT.
Ya no tiene excusa para incluir en su web una verdera galería de imágenes 2.0.
Internacionalización y Localización (i18n – l10n): Cómo localizar una web en php
Cómo subir las visitas o el tráfico de visitantes de una web
Cómo funciona Google: la búsqueda, indexación y ordenación de las páginas
Como ya vimos en el artículo cómo funciona Google 1: el proceso de búsqueda, el éxito de este buscador reside en su propia naturaleza que le permite atender casi instantáneamente miles de peticiones de búsqueda por segundo. En esta ocasión vamos a detenernos en el proceso de búsqueda, indexación y ordenación de las páginas:
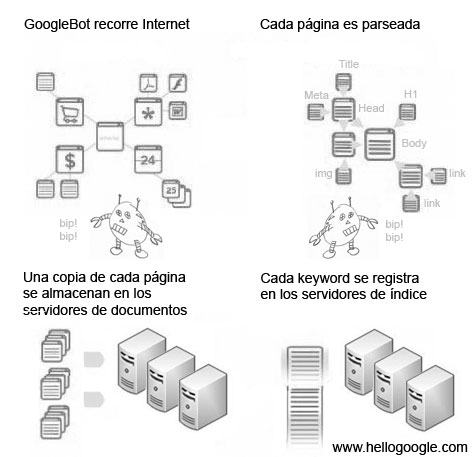
- Búsqueda y Parsing (parseo): Google debe ser capaz de recorrer Internet, procesar e interpretar correctamente todos los documentos que encuentre. Por este motivo necesita solventar correctamente cualquier error o problema que encuentre en un documento: manejar caracteres no ASCII, Tags incorrectos o mal anidados, múltiples tipos de documentos y muchos otros problemas que desafiarían a las mentes más retorcidas. La búsqueda y el parsing lo realiza, como veremos más adelante, el GoogleBot.
- Indexación de los keywords y documentos: Cuando un documento es parseado, cada una de las palabras que lo conforman se almacenan en un índice que pemitirá a Google manejar miles de terabytes de información de manera realmente ágil y eficiente.
- Ordenación: Finalmente y antes de poderle ofrecer el resultado de su búsqueda, Google deberá ordenar todos los documentos en función de su importancia. Como veremos adelante existen múltiples factores que determinan la posición de un documento en la página de resultados.
Deep crawling: el proceso de indexación de las páginas
Googlebot: La araña de Google.
Googlebot es el nombre de la aplicación de Google que navega las 24 horas del día visitando los miles de millones de páginas que habitan Internet, como si de un incansable usuario se tratase. Aunque, estrictamente hablando, Googlebot no navega por Internet como lo hace un ser humano; Una vez que ha accedido a una web la almacena en sus servidores de documentos y le asigna un identificativo único, a continuación busca todos sus enlaces y prosigue su navegación accediendo e indexando estos nuevos documentos que procesa de manera idéntica. Está técnica se denomina deep crawling y es similar a una araña que va tejiendo su tela (por este motivo a este tipo de programas se les denominen arañas.)
Un dato curioso: Googlebot es incluso capaz de cumplimentar los campos de un formulario, para poder acceder a las páginas que de otra manera serían inaccesibles.
Googlebot tiene tal potencia que si funcionara al 100% de su capacidad, podría saturar con sus peticiones cualquier servidor web. Por este motivo funciona deliberadamente muy por debajo de su capacidad real. En este sentido, Googlebot es realmente educado, ¿no cree?

GoogleBot: Yo domino el mundo!
Cada vez que el Googlebot encuentra un documento html realiza un parsing o parseo para extraer e interpretar la información. HTML no es un lenguaje de programación, si no un lenguaje de marcación que permite enriquecer el texto plano con una serie de etiquetas que en algunos casos imprime un valor semántico al texto que alberga. HTML también permite ordenar jerárquicamente la información de una página con titulares, subtitulares, listas, etc…
El parsing de un documento consiste precisamente en interpretar esta información para ser capaz de conocer de conocer cuál fue la intención del autor cuando lo escribió y extraer los keywords más relevantes. De esta manera no debería tener la misma relevancia para google la frase «Los mejores complementes para la mujer» como titular de una página que si aparece al pie de una foto.
Como posiblemente ya haya deducido, la optimización orgánica de un Site consiste en codificar el HTML de tal manera que Google sea capaz de valorar positivamente su contenido. Para ello debemos saber cómo utilizar los tags de cabecera, cómo destacar información con tags semánticos, incluir alts en las imágenes, optimizar los títulos, cuidar la meta información, etc. Puede ampliar esta información en el siguiente artículo sobre posicionamiento web.
Google visita con mayor frecuencia algunas páginas populares que sabe que actualizan su información de forma muy dinámica: periódicos, boletines, tiendas on-line, etc. Este tipo de indexación se denomina fresh crawling.
Una manera de facilitar la labor del Googlebot a la hora de indexar nuestras páginas son los Google SiteMaps. Se trata de un documento XML en el que podemos informar activamente al robot de Google sobre las páginas que conforman nuestro Sitio Web. Adicionalmente los Google SiteMaps ofrecen al webmaster estadísticas de acceso del robot y posibles errores de indexación.
También podemos enviar a Googlebot la dirección de una página indicando la URL en el formulario www.google.com/addurl.html.
El proceso de búsqueda de Google paso a paso.
Los servidores de índice.
El siguiente paso consiste en generar un índice para organizar y catalogar todos los documentos web que Googlebot ha encontrado. Este índice es el que permite a Google responder de manera casi instantánea a nuestras búsquedas, devolviéndonos todos los documentos relacionados con nuestra solicitud. Sin este índice Google necesitaría recorrer una a una todos los páginas almacenadas en sus servidores de documentos y le llevaría varias horas atender cada petición.
Los servidores de índices contienen una entrada por cada uno de los keywords o palabras que aparecen en los documentos que GoogleBot encuentra. Los índices contemplan cualquier término de búsqueda en cualquier idioma, por lo que para mejorar la eficiencia de sus índices Google ignora todos los términos demasiado generales: preposiciones, artículos, conjunciones, símbolos de puntuación, espacios dobles, etc. A estos keywords poco relevantes les denomina stop words.
Los servidores de índice de Google permiten a Google conocer de todos los documentos que contienen un keyword concreto. Por ejemplo, podríamos tener una entrada del índice para la palabra «bolso» asociada a los documentos 5, 8, 102, 203, 256 y 430. De igual manera la palabra «piel» podría estar asociada a los documentos 12, 34, 102, 203, 213, 256 y 430, y la palabra «mujer» aparecería en los documentos 8, 23, 102, 234, 390, 394, 430 y 516.
| Keyword | documentos |
| bolso | 5 8 102 203 256 430 |
| piel | 12 34 102 203 213 256 430 |
| mujer | 8 23 102 234 256 394 430 516 |
| … | … |
Para agilizar las consultas a su índice y poder conocer de manera inmediata qué documentos están relacionados con un keyword, Google distribuye la información en cientos de ordenadores que trabajan en paralelo. Imagínese que usted está leyendo un libro sobre complementos de moda que contiene un índice de 100 páginas. Si una persona tuviera que encontrar cierta información, por ejemplo bolsos de piel de mujer, necesitaría leer detenidamente las cien páginas del índice. En cambio si distribuye la tarea entre 100 personas, cada uno de ellos tan sólo necesita leer una página del índice. De esta misma manera actúa Google.
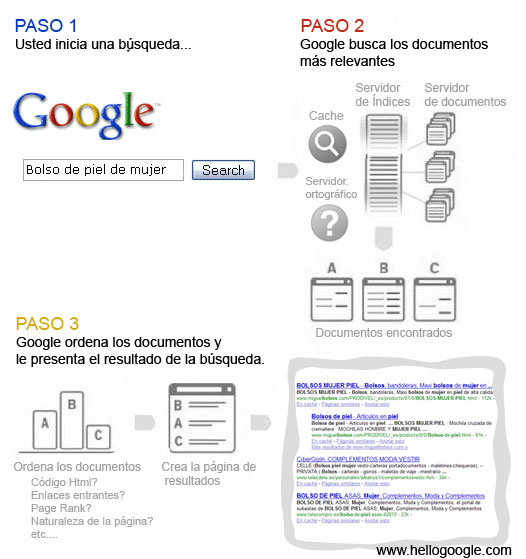
El orden de los resultados.
Hemos visto que el índice permite a Google conocer qué documentos están relacionados con los keywords de una búsqueda. Por ejemplo, imaginemos que usted accede a Google e introduce el término de búsqueda: «bolsos de piel de mujer«. La lista de documentos que contienen una de los keywords de la búsqueda se denomina «lista de publicación» y las listas de publicación que contienen todos los keywords de la búsqueda se denomina «intersección de listas de publicación«.
Para agilizar la intersección de varias listas de publicación, se recorren simultáneamente los documentos de cada una. Si , por ejemplo, una de las listas no contiene documentos entre los índices 8 y 102, podemos saltar en todas las listas hasta el índice 102.
Según nuestro índice, los documentos que contienen los keywords de la búsqueda son el 102, 256 y 430.
| Keyword | documentos |
| bolso | 5 8 102 203 256 430 |
| piel | 12 34 102 203 213 256 430 |
| mujer | 8 23 102 234 256 394 430 516 |
| … | … |
Ahora bien, antes de presentar al usuario el resultado de la búsqueda es necesario ordenar los documentos en función de su relevancia. Google siempre intentar ofrecer las páginas más relevantes e importantes para la búsqueda.Si varias páginas ofrecen información igualmente relevante para la entrada introducida, Google ponderará entonces otros factores:
- La entidad de las páginas que la enlazan.
- La estructura orgánica de la página.
- El page rank (marca patentada)
- En ocasiones la naturaleza de la propia página puede ser más determinante que el page rank o los enlaces entrantes. Por ejemplo un Site dedicado por completo a complementos de mujer será generalmente más útil que un artículo de opinión sobre las costumbres tribales de un poblado africano que confecciona bolsos con piel de mujer.
Los resultados de las búsquedas más populares son mantenidas en una cache durante horas, para evitar tener que repetir el proceso una y otra vez. Así si usted quiere buscar información sobre Britney Spears, el proceso de búsqueda será muy rápido para Google.
La precisión de de Google es tal, que puede advertir si existe un error ortográfico en una búsqueda y proponerle una búsqueda alternativa. Esto lo consigue gracias a sus servidores ortográficos que son capaces de determinar el idioma y si cambiando alguna letra al término de búsqueda se incrementa de manera sustancial el número de resultados.
Como puede ver, Google se comporta como una gran orquesta, en la que todos sus músicos participan de manera armónica y acompasada para ofrecernos a todos sus usuarios millones de sinfonías al día. Sinfonías en forma de búsquedas que en a penas medio segundo ofrecen un claro ejemplo de técnica, oficio y precisión.
Cómo funciona Google: el proceso de búsqueda
La verdadera magia de Google reside en su concepción de la web: Google nunca ha entendido la web como un conjunto de documentos de texto, si no como un conjunto de relaciones entre documentos de texto y cada una de éstas relaciones constituye verdaderamente la esencia de Google. En este artículo de HelloGoogle veremos cómo se desarrolla todo el proceso de búsqueda:
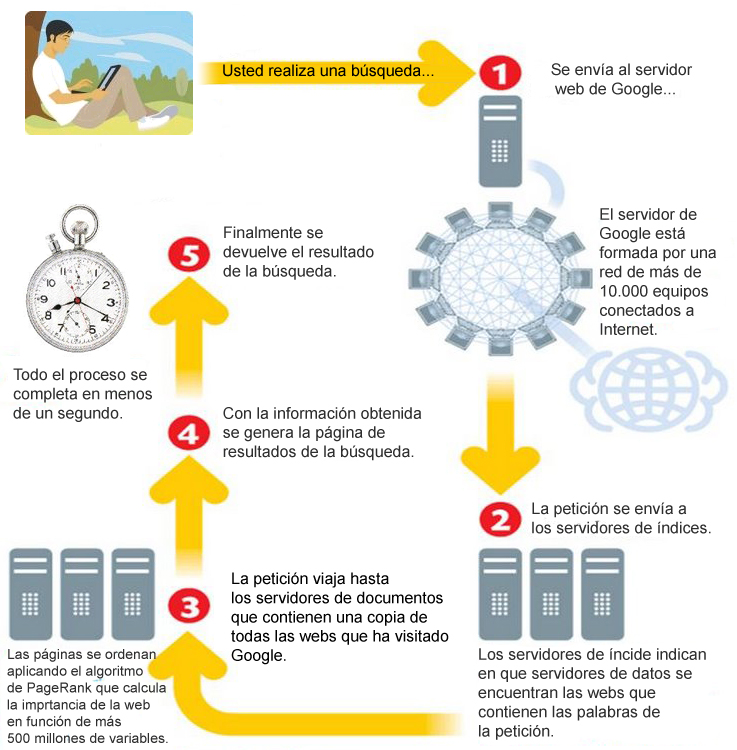
Cuando escribimos una búsqueda en www.google.com nuestra petición viaja por el hiperespacio hasta el servidor web de Google. Google recibe más de 1000 peticiones de búsqueda cada segundo de todos los días del año:
- El servidor web de Google está formado por una red de más de 10.000 equipos trabajando en paralelo.
- Cada servidor de la red de Google es extremadamente sencillo y económico: PCs con procesadores X86, disco duro IDE y demás prestaciones estándar.
- El bajo coste del hardware es la base del modelo de negocio de Google y lo que le permite ofrecer la mayoría de sus servicios de manera gratuita.
- Cada servidor falla una vez cada tres años.
- Cada día fallan dos servidores.
- Si se produce cualquier problema de hardware, el software de Google lo hace imperceptible para sus usuarios.
- Google no ha sufrido un fallo general desde el año 2000.
A continuación se envía la consulta a los servidores de índices de Google. Cada índice está formado por una relación entre una palabra y la dirección del servidor de documentos de Google donde se almacenan las páginas que contienen dicha palabra.
- Cada servidor de índices contiene sólo una parte de las webs de Internet y son necesarios varios servidores trabajando en paralelo para calcular el resultado de la búsqueda.
Con la información de los índices se accede a los servidores de documentos de Google que contienen una copia de cada web indexada.
- Google contiene más de 4000 millones de páginas, por cada página almacena 10KB de información, lo que supone 40 Terabytes de información.
- Google dispone de 50 mirrows (replicas) por cada servidor.
Por último se aplica el algoritmo de PageRank para ordenar los resultados de la búsqueda por relevancia. El algoritmo de PR calcula la relevancia de una web gracias a 2 billones de ecuaciones con más de 500 millones de variables.
Con toda esta información se crea y muestra al usuario la conocida página de resultados SERP, merece la pena mencionar que Google completa todo este proceso de búsqueda en menos de 1 segundo.