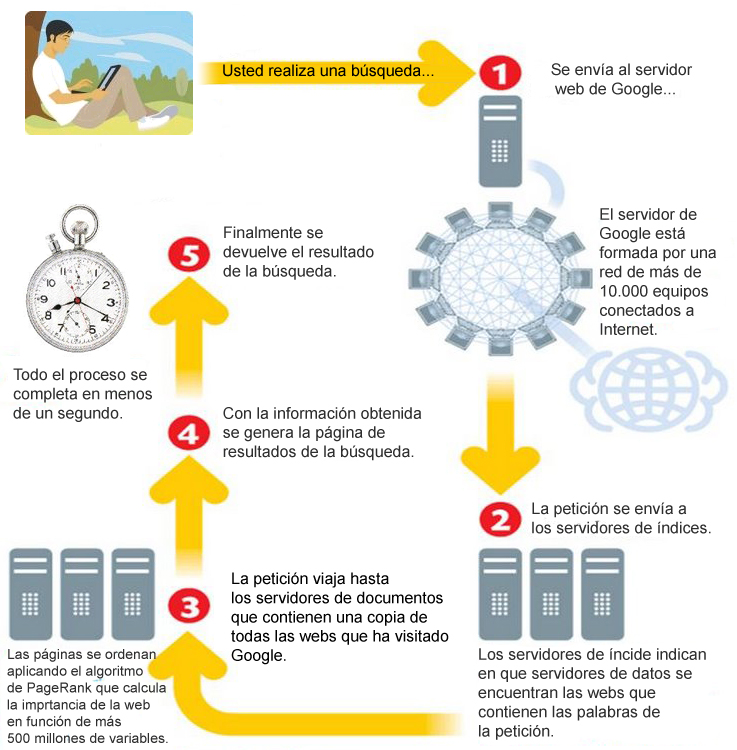
La verdadera magia de Google reside en su concepción de la web: Google nunca ha entendido la web como un conjunto de documentos de texto, si no como un conjunto de relaciones entre documentos de texto y cada una de éstas relaciones constituye verdaderamente la esencia de Google. En este artículo de HelloGoogle veremos cómo se desarrolla todo el proceso de búsqueda:
Cuando escribimos una búsqueda en www.google.com nuestra petición viaja por el hiperespacio hasta el servidor web de Google. Google recibe más de 1000 peticiones de búsqueda cada segundo de todos los días del año:
- El servidor web de Google está formado por una red de más de 10.000 equipos trabajando en paralelo.
- Cada servidor de la red de Google es extremadamente sencillo y económico: PCs con procesadores X86, disco duro IDE y demás prestaciones estándar.
- El bajo coste del hardware es la base del modelo de negocio de Google y lo que le permite ofrecer la mayoría de sus servicios de manera gratuita.
- Cada servidor falla una vez cada tres años.
- Cada día fallan dos servidores.
- Si se produce cualquier problema de hardware, el software de Google lo hace imperceptible para sus usuarios.
- Google no ha sufrido un fallo general desde el año 2000.
A continuación se envía la consulta a los servidores de índices de Google. Cada índice está formado por una relación entre una palabra y la dirección del servidor de documentos de Google donde se almacenan las páginas que contienen dicha palabra.
- Cada servidor de índices contiene sólo una parte de las webs de Internet y son necesarios varios servidores trabajando en paralelo para calcular el resultado de la búsqueda.
Con la información de los índices se accede a los servidores de documentos de Google que contienen una copia de cada web indexada.
- Google contiene más de 4000 millones de páginas, por cada página almacena 10KB de información, lo que supone 40 Terabytes de información.
- Google dispone de 50 mirrows (replicas) por cada servidor.
Por último se aplica el algoritmo de PageRank para ordenar los resultados de la búsqueda por relevancia. El algoritmo de PR calcula la relevancia de una web gracias a 2 billones de ecuaciones con más de 500 millones de variables.
Con toda esta información se crea y muestra al usuario la conocida página de resultados SERP, merece la pena mencionar que Google completa todo este proceso de búsqueda en menos de 1 segundo.
Muy buena la imagen, gracia por compartirla y ayudar a entender mejor el funcionamiento del motor de Gooogle 😉
Gracias a ti por tu comentario.
Hola espero que te pases por mi site y leas la contestacion a tu ultimo comentario saludos y espero solucionar esto 😉 el tema de los enlaces ya esta resuleto pero como un compañero mio fue el que te cojio las entradas no se cuales son y cuales no modifique las que vi tu comentario, poniendoles la fuente espero que te pases venga hasta otra salu2
Cuidadín con esas traducciones:
1 billion = 1.000 millones
Donde dice: «Google contiene más de 4 billones de páginas, por cada página almacena 10KB de información, lo que supone 40 Terabytes de información.»
Debe de decir: «4 mil millones de páginas»
4.000 millones de páginas a 10.000 bytes cada una, nos da 40 billones de bytes, o lo que es lo mismo, 40 TB.
Hola Antonio, gracias por la corrección. Ya he actualizado el post.
Muy util tu nota
He visto en otras paginas que el numero de paginas indexadas por google , pasan los 8 mil millones ! las informaciones en esta pagina son de que fecha???
Gracias por poner al dia estas informaciones.
Ignacio ¿no crees que el Page Rank desde hace tiempo ya no tiene nada que ver en el orden que apareceran nuestras palabras clave? Por mi experiencia, google me mantiene un PR de 4 y sin embargo me baja posiciones en palabras.
Hola Euribor, cuando tengas un rato echa un ojo al artículo http://www.hellogoogle.com/mejorar-subir-pagerank-google/ aquí explico para qué sirve y para qué no sirve el PR.
Un saludo.
Estoy haciendo un trabajo para la universidad y tu explicacion es buenisima. Gracias por compartir esta informacion.
Suerte con el trabajo Susana.
Un saludo.
Escelente aporte, ahora si entendi mas o menos como funciona este buscador, me explicaba como podia encontrar millones de resultados en menos de un segundo. Pensaba que como hacian para meterse en todas las paginas de internet y buscar las palabras tan rapido si en mi computadora para buscar un archivo en un disco duro de 500 GB duraba mas o menos 1 minuto, pero ahora de comprendi, Muchas Gracias.
Bueno, puedes probar Google Desktop que tiene un funcionamiento similar al motor de Google pero aplicado a tu PC.
Un saludo.
Excelente el informe del proceso de búsqueda. Superimportante, me estoy dando cuenta que lo que yo suponia del trabajo de Google es una realidad, «relaciones e indexación de paginas».
Yandel Wisin, Videos y mucho mas… solo, Wisin y Yandel.
HernanM
muy buena la forma de ilustrar el proceso de búsqueda! gracias
como funciona google
En primer lugar, la explicación me ha resultado muy esclarecedora.
Mi pregunta: hay un blog que ahora ya no está activo y del que Google ya no tiene nada en su caché, pero que sin embargo al hacer una búsqueda indicándole el site en donde debe buscar, sí devuelve resultados.
¿Se puede recuperar de algún modo de la base de datos de índices de Google todos aquellos índices que le fueron asociados una web, junto a las dos líneas en las que aparece el término buscado, pasándole la url de la misma?
El objetivo sería recuperar la mayor parte posible del texto contenido en ese blog, la última vez que fue indexado por googlebot.
Gracias
uff! me sirvio gracias super didactico………….
As long as they are not tagged “nofollow”.
Once crawled, the page is indexed within seconds.
Page content is stored in a reverse index.
On page content is stored in another index used for obscure and long tail searches.
Page titles and link data are stored in one index used for broad and competitive searches.
When you search google you are not searching the active web, but Google´s cache of it, which is constantly being updated.
Google estimates the domain and page´s overall authority based on links.
Pages are checked against editorial policies.
Google´s search Quality team and Webspam team review and refine algorithms.
10,000 remote testers rate the quality of their searches.
Google solicits spam reports from users.
Google gets DMCA notifications to take down pirated work.
Penalties are applied and each page now has many pieces of data attache to it that help in user searches.
Users queries Goolge.
“On most Goolge queries, you´re actually in multiple control or experimental groups simultaneously… Essentially, all the queries are involved in some test.” -Patrick Riley, Google search quality engineer.
Google suggests keywords based on what has been typed so far.
Google uses synonyms to look for similar words to include in the search query.
Initial result set is created.
Google may claim millions of results but only 1,000 or less are ever displayed.
Result localization: Local websites are promoted in the search results.
Result set is sorted by authority and PageRank and duplicate pages are removed.
Google finds relevant ads based on keywords, ad match type and user location.
Ads are subject to editorial policy…………………..
Una informacion muy util y interesante.
Un articulo muy interesante, el proceso de busqueda parece sencillo pero no lo es,
bastante buena la informacion, me ayudo mucho en una investigacion suerte amigo
es muy interesante la informacion
Suena de película todo el proceso que hay tras una búsqueda, sin embargo en cuestión de segundos sucede ese fantástico proceso.
Por haí dicen que una imagen vale más que mil palabras. Y no cabe duda. Con el esquema diseñado y con una breve explicación por escrito ya tengo una idea más clara de cómo hace esta máquina para responder en unos tiempos tan pequeños a la luz de mi mente. Considero que es necesario buscar otros terminos usados en la descripción del funcionamiento del buscador, tales como, semantica, indexación y otros hasta lograr un entendimiento real de lo que significan éstos procedimientos y estas máquinas que están ayudando a que el ser humano de ese paso evolutivo que hará que perdure otro lapso de tiempo más en este planeta pero en otras condiciones de sobrevivencia-